NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
ECC Support
AMD's Radeon HD 5870 can detect errors on the memory bus, but it can't correct them. The register file, L1 cache, L2 cache and DRAM all have full ECC support in Fermi. This is one of those Tesla-specific features.
Many Tesla customers won't even talk to NVIDIA about moving their algorithms to GPUs unless NVIDIA can deliver ECC support. The scale of their installations is so large that ECC is absolutely necessary (or at least perceived to be).
Unified 64-bit Memory Addressing
In previous architectures there was a different load instruction depending on the type of memory: local (per thread), shared (per group of threads) or global (per kernel). This created issues with pointers and generally made a mess that programmers had to clean up.
Fermi unifies the address space so that there's only one instruction and the address of the memory is what determines where it's stored. The lowest bits are for local memory, the next set is for shared and then the remainder of the address space is global.
The unified address space is apparently necessary to enable C++ support for NVIDIA GPUs, which Fermi is designed to do.
The other big change to memory addressability is in the size of the address space. G80 and GT200 had a 32-bit address space, but next year NVIDIA expects to see Tesla boards with over 4GB of GDDR5 on board. Fermi now supports 64-bit addresses but the chip can physically address 40-bits of memory, or 1TB. That should be enough for now.
Both the unified address space and 64-bit addressing are almost exclusively for the compute space at this point. Consumer graphics cards won't need more than 4GB of memory for at least another couple of years. These changes were painful for NVIDIA to implement, and ultimately contributed to Fermi's delay, but necessary in NVIDIA's eyes.
New ISA Changes Enable DX11, OpenCL and C++, Visual Studio Support
Now this is cool. NVIDIA is announcing Nexus (no, not the thing from Star Trek Generations) a visual studio plugin that enables hardware debugging for CUDA code in visual studio. You can treat the GPU like a CPU, step into functions, look at the state of the GPU all in visual studio with Nexus. This is a huge step forward for CUDA developers.
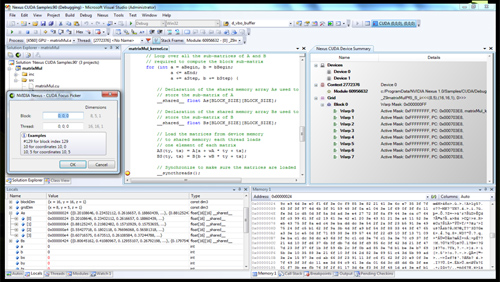
Nexus running in Visual Studio on a CUDA GPU
Simply enabling DX11 support is a big enough change for a GPU - AMD had to go through that with RV870. Fermi implements a wide set of changes to its ISA, primarily designed at enabling C++ support. Virtual functions, new/delete, try/catch are all parts of C++ and enabled on Fermi.








415 Comments
View All Comments
samspqr - Thursday, October 1, 2009 - link
ATI's availability will be sorted out soon, NVIDIA's weird design choices that are targeted at anything but graphics won'tin fact, I have just realized: NVIDIA IS DOING A MATROX!
(forget about graphics, concentrate in a proffessional niche, subsequently get run over by competitors in its former main market... eventually dissappear from the graphics market or become irrelevant? with some luck, RayTracing will be here sooner rather than later, ATI will switch to GPUcomputing at the right time -as opposed to very much too soon-, and we will have a 3 players market; until then, ATI domination all over)
andrihb - Thursday, October 1, 2009 - link
What a huge leap of the imagination :Psamspqr - Friday, October 2, 2009 - link
sorry, I was just trying to imagine how many weird things would have to happen so that we don't have a single GPU maker in the marketin any case, if you want some imaginative thinking, try here:
http://www.semiaccurate.com/2009/10/01/nvidia-fake...">http://www.semiaccurate.com/2009/10/01/nvidia-fake...
(I'm not sure yet who is the one making stuff up -charlie or nvidia-, but so far my bet would be on nvidia)
mindless1 - Saturday, October 3, 2009 - link
What they may have done is take an existing PCB design for something else, and tacked down the parts and air-wired them. It is a faster way to debug a prototype, as well as just drilling a few holes and putting makeshift screws in to test a cooling design before going to the effort of the rest of the support parts before you know if the cooling subsystem is adequate.IF that is the situation, I feel nVidia should have held off until they were further along with the prototypes, but when all is said and done if they can produce performance in line with the expectations, that would prove they had a working card.
IGoodwin - Friday, October 2, 2009 - link
First off, I don't know the truth about a fake or real Tesla being in existence; however, when an article shows a strong emotional bias, I do find it hard to accept the conclusions.Here is a link to the current Tesla product for sale online:
http://www.tigerdirect.com/applications/SearchTool...">http://www.tigerdirect.com/applications...tails.as...
This clearly shows the existing Tesla card with screws on the end plate. Also, if memory serves, having partial venting on a single slot for the new Tesla card would equal the cooling available on the ATI card. Also, six-pin connector is in roughly the same place.
As for the PCB, it is hidden on the older Tesla screen shots, so nothing can be derived.
The card may be fake, or not, but Charlie is not exactly unbiased either.
jonGhast - Saturday, October 3, 2009 - link
"but Charlie is not exactly unbiased either."What's the deal with that, I keep trying to read Semi's articles, though his 'tude towards MS and Intel is pretty juvenile, but I've got to ask; did somebody at Nvidia gang rape his mom?
mindless1 - Saturday, October 3, 2009 - link
I simply assume he is either directly or indirectly on ATI's payroll.Fudzilla wrote "The real engineering sample card is full of dangling wires." To display such a card to others they could simply epoxy down some connectors and solder the wires to them.
monomer - Friday, October 2, 2009 - link
Here's an article from Fudo saying that the card was a mock-up. Nvidia claimed it was real at the conference, and are now saying its a fake, but that they really, truly, had a real one running the demos. Really! I completely believe them.http://www.fudzilla.com/content/view/15798/1/">http://www.fudzilla.com/content/view/15798/1/
Yojimbo - Thursday, October 1, 2009 - link
What makes you think it isn't the right time? You can only really tell in hindsight, but you give in your post any reason that you think now is not the right time and later, when amd is gonna do it, is the right time. I think the right time is whenever the architecture is available and the interest is there. Nvidia has, over the past 5 years, been steadily building the architecture for it. Whether the tools are all in place yet and whether the interest is really there remains to be seen.It has nothing to do with matrox or any shift to a "professional niche." Nvidia believes that it has the ability to evolve and leverage its products from the niche sector of 3d graphics into a broader and more ubiquitous computing engine.
wumpus - Thursday, October 1, 2009 - link
Do you see any sign of commercial software support? Anybody Nvidia can point to and say "they are porting $important_app to openCL"? I haven't heard a mention. That pretty much puts Nvidia's GPU computing schemes solely in the realm of academia (where you can use grad students a cheap highly-skilled labor). If they could sell something like a FEA package for pro-engineer or solidworks, the things would fly off the shelves (at least I know companies who would buy them, but it might be more a location bias). If you have to code it yourself, that leaves either academia (which mostly just needs to look at hardware costs) and existing supercomputer users. The existing commercial users have both hardware and software (otherwise they would be "potential users"), and are unlikely to want to rewrite the software unless it is really, really, cheaper. Try to imagine all the salaries involved in running the big, big, jobs Nvidia is going after and tell me that the hardware is a good place to save money (at the cost of changing *everything*).I'd say Nvidia is not only killing the graphics (with all sorts of extra transistors that are in the way and are only for double point), but they aren't giving anyone (outside academia) any reason to use openCL. Maybe they have enough customers who want systems much bigger than $400k, but they will need enough of them to justify designing a >400mm chip (plus the academics, who are buying these because they don't have a lot of money).