NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
ECC Support
AMD's Radeon HD 5870 can detect errors on the memory bus, but it can't correct them. The register file, L1 cache, L2 cache and DRAM all have full ECC support in Fermi. This is one of those Tesla-specific features.
Many Tesla customers won't even talk to NVIDIA about moving their algorithms to GPUs unless NVIDIA can deliver ECC support. The scale of their installations is so large that ECC is absolutely necessary (or at least perceived to be).
Unified 64-bit Memory Addressing
In previous architectures there was a different load instruction depending on the type of memory: local (per thread), shared (per group of threads) or global (per kernel). This created issues with pointers and generally made a mess that programmers had to clean up.
Fermi unifies the address space so that there's only one instruction and the address of the memory is what determines where it's stored. The lowest bits are for local memory, the next set is for shared and then the remainder of the address space is global.
The unified address space is apparently necessary to enable C++ support for NVIDIA GPUs, which Fermi is designed to do.
The other big change to memory addressability is in the size of the address space. G80 and GT200 had a 32-bit address space, but next year NVIDIA expects to see Tesla boards with over 4GB of GDDR5 on board. Fermi now supports 64-bit addresses but the chip can physically address 40-bits of memory, or 1TB. That should be enough for now.
Both the unified address space and 64-bit addressing are almost exclusively for the compute space at this point. Consumer graphics cards won't need more than 4GB of memory for at least another couple of years. These changes were painful for NVIDIA to implement, and ultimately contributed to Fermi's delay, but necessary in NVIDIA's eyes.
New ISA Changes Enable DX11, OpenCL and C++, Visual Studio Support
Now this is cool. NVIDIA is announcing Nexus (no, not the thing from Star Trek Generations) a visual studio plugin that enables hardware debugging for CUDA code in visual studio. You can treat the GPU like a CPU, step into functions, look at the state of the GPU all in visual studio with Nexus. This is a huge step forward for CUDA developers.
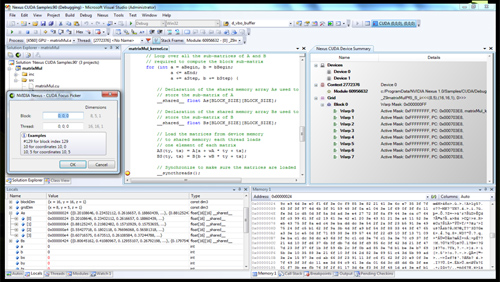
Nexus running in Visual Studio on a CUDA GPU
Simply enabling DX11 support is a big enough change for a GPU - AMD had to go through that with RV870. Fermi implements a wide set of changes to its ISA, primarily designed at enabling C++ support. Virtual functions, new/delete, try/catch are all parts of C++ and enabled on Fermi.








415 Comments
View All Comments
Inkie - Saturday, October 3, 2009 - link
Not that I really want to support SD here, but there was working silicon there. It's kind of weird that many sites fail to mention this. Instead, they focus on the mockup.SiliconDoc - Thursday, October 1, 2009 - link
Go read a few articles on how a card is developed, and you'll have the timeline, you red rooster retard.I mean really, I'm talking to ignoramussed spitting cockled mooks.
Please, the articles are right here on your red fan website, so go have a read since it's so important to you how people act when your idiotic speculation is easily and absolutely 100% incorrect, and it's PROVEABLE, the facts are already IN.
gx80050 - Friday, October 2, 2009 - link
You're a fucking friendless loser who should have died on 9/11. Fucking cuntmonomer - Friday, October 2, 2009 - link
In reply to your original link, here's a retraction, of sorts:http://www.fudzilla.com/content/view/15798/1/">http://www.fudzilla.com/content/view/15798/1/
The card Nvidia showed everyone, and said was Fermi is in fact a mock-up. Oh well.
silverblue - Thursday, October 1, 2009 - link
What facts? What framerates can it manage in Crysis? What scores in 3DMark? How good it is at F@H?Link us, so we can all be shown the errors of our ways. It's obvious that GT300 has been benchmarked, or at least, it's only obvious to you simply because the rest of us are on a different planet.
You call people idiots, and then when they reply in a sensible manner, you conveniently forget all that and call them biased (along with multiple variations on the red rooster theme). You're like a scratched vinyl record and it's about time you got off this site if you hate its oh-so-anti-nVidia stance that doesn't actually exist except in your head.
Prove us wrong! Please! I want to see those GT300 benchmarks! Evidence that Anandtech are so far up AMD's rear end that nothing else is worth reporting on fairly!
Zool - Thursday, October 1, 2009 - link
GTX285 had 32 ROPs and 80 TMUs for aorund the same bandwith like 5870 with same 32 ROPs and 80 TMUs. Dont be stupid. GTX will surely need more ROPs and TMUs if they want to keep up with graphic even with the GPGPU bloat.Totally - Wednesday, September 30, 2009 - link
it's 225GB/s not 230.4/s230400/1024 = 225
I'm afraid your bad at math.
Lightnix - Thursday, October 1, 2009 - link
Nope, just really bad at remembering that those prefixes mean 1024 at like 1 in the morning.Lonyo - Wednesday, September 30, 2009 - link
You assume that they will use GDDR5 clocked at the same speed as ATI.They could use higher clocked GDDR5 (meaning even more bandwidth), or lower clocked GDDR5 (meaning less bandwidth).
There's no bandwidth comparison because 1) it's meaningless and 2) it's impossible to make an absolute comparison.
NV will have 50% more bandwidth if the speed of the RAM is the same, but it doesn't have to be the same, it could be higher, or lower, so you can't say what absolute numbers NV will have.
I could make a graph showing equal bandwidth between the two cards even though NV has a bigger bus, or I could make one showing NV having two times the bandwidth despite only a 50% bigger bus.
Both could be valid, but both would be speculative.
Calin - Thursday, October 1, 2009 - link
Also, there could be a chance that the Fermi chip doesn't need/use much more bandwidth than the GT200. Available bandwidth does not performance make