NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
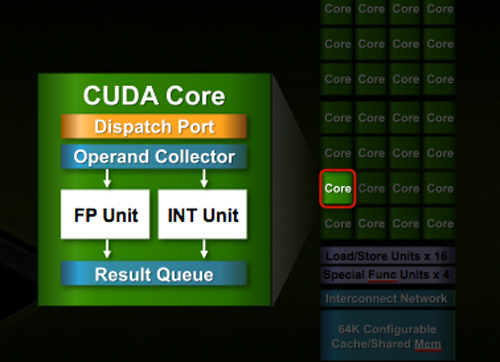
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
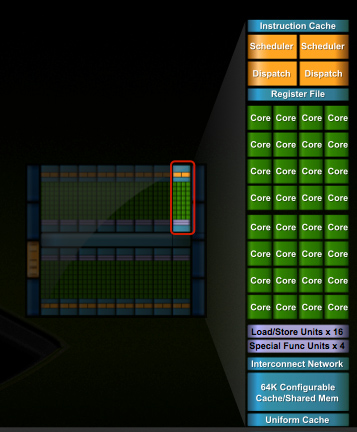
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
rennya - Thursday, October 1, 2009 - link
I have already countered your suggestion that ATI 5870 is just a paper launch, somewhere in this same discussion.Plus, if nVidia really has working silicon as you showed in the fudzilla link, where then I can buy it? Even at the IDF, Intel shows working silicon for Larrabee (although older version), but not even the die-hard Intel fanboys will claim that Larrabee will be available soon.
SiliconDoc - Thursday, October 1, 2009 - link
Gee, we have several phrases. Hard launch, and paper launch. Would you prefer something in between like soft launch ?Last time nvidia had a paper launch, that what everyone called it and noone had a problem, even if cards trickled out.
So now, we need changed definitions and new wordings, for the raging little lying red roosters.
I won't be agreeing with you, nor have you done anything but lie, and attack, and act like a 3 year old.
It's paper launch, cards were not in the channels on the day they claimed they were available. 99 out of 100 people were left bone dry, hanging.
Early today the 5850 was listed, but not avaialable.
Now, since you people and this very site taught me your standards and the definition and how to use it, we're sticking to it when it's a god for saken red rooster card, wether you like it or not.
rennya - Friday, October 2, 2009 - link
You defined hard launch as having cards on retail shelf.That's what happened here in the first couple of days at the place I lived in. So, according to your standard, 5870 is a hard launch, not paper launch or soft launch. I can easily get one if I want to (but my casing is just crappy TECOM mid-tower, the card will not fit).
As far as I am concerned, 5870 has a successful hard launch. You tried to tell people otherwise, that's why I called you a liar.
Where to know where I live? Open up the Lynnfield review at http://www.anandtech.com/cpuchipsets/showdoc.aspx?...">http://www.anandtech.com/cpuchipsets/showdoc.aspx?... then look at the first picture in the first page. It shows you the country where I am posting this post from. The same info can also be seen in AMD Athlon X4 620 review at http://www.anandtech.com/cpuchipsets/showdoc.aspx?...">http://www.anandtech.com/cpuchipsets/showdoc.aspx?... . The markup from MRSP can be ridiculous sometimes, but availability is not a problem.
Zingam - Thursday, October 1, 2009 - link
This CPU is for what? Oh, Tesla - the things that cost 2000 :) And the consumers won't really get anything more by what ATI offers currently!Seems like it is time for ATI to do a paper launch.
Just to inform the fanboys: ATI has already finalized the specs for generation 900 and 1000. The current is just 800.
So on paper, dudes, ATI has even more than what they are displaying now!
BTW who said: DX11 won't matter?? :)
cactusdog - Thursday, October 1, 2009 - link
Its unbelievable that Nvidia wont have a DX11 chip in 2009. Massive fail.strikeback03 - Thursday, October 1, 2009 - link
Not if there are no worthwhile DX11 games in 2009.yacoub - Wednesday, September 30, 2009 - link
"Perhaps Fermi will be different and it'll scale down to $199 and $299 price points with little effort? It seems doubtful, but we'll find out next year."Yeah okay, side with their marketing folks. God forbid they actually release reasonably-priced versions of Fermi that people will actually care to buy.
SiliconDoc - Thursday, October 1, 2009 - link
Derek did an article not long ago on the costs of a modern videocard, and broke it down part and piece by cost, each.Was well done and appeared accurate, and the "margin" for the big two was quite small. Tiny really.
So people have to realize fancy new tech costs money, and they aren't getting raked over the coals. its just plain expensive to have a shot to the moon, or to have the latest greatest gpu's.
Back in '96 when I sold a brand new computer I doubled my investment, and those days are long gone, unles you sell to schools or the government, then the upside can be even higher.
yacoub - Thursday, October 1, 2009 - link
And yet all of that is irrelevant if the product cannot be delivered at a price point where most of the potential customers will buy it. You're forgetting that R&D costs are not just "whatever they will be" but are based off what the market will support via purchasing the end result. It all starts withe the consumer. You can argue all you want that Joe Gamer should buy a $400 GPU but he's only capable of buying a $300 GPU and only willing to buy a $250 GPU, then you're not going to get a sale until you cross the $300 threshold with amazing marketing and performance or the $250 threshold with solid marketing and performance. Companies go bust because they overspend on R&D and never recoup the cost because they can't price the product properly for it to sell the quantities needed to pay back the initial investment, let alone turn a significant profit.Arguing that gamers should just magically spend more is silly and shows a lack of understanding of economics.
SiliconDoc - Thursday, October 1, 2009 - link
Well I didn't argue that gamers should magically spend more.--
I ARGUED THAT THE VIDEOCARDS ARE NOT SCALPING THE BUYERS.
---
Deerek's article, if you had checked, outlined a card barely over $100.00
But, you instead of thinking, or even comprehending, made a giant leap of false assuming. So let me comment on your statements, and we'll see where we agree.
--
1. Ok, the irreverance(yes that word) here is that TESLA commands a high price, and certainly has been stated to be the profit margin center (GT200) for NVIDIA- so...whatever...
- Your basic points are purely obvious common sense, one doesn't even need state them - BUT - since Nvidia has a profit driver where ATI does not, if you're a joe rouge, admitting that shouldn't be the crushing blow it apparently is.
2. Since Nvidia has been making the MONEY, the PROFIT, and reinvesting, I think they have a handle on what to spend, not you, and their sales are much higher up to recoup costs, not sales, to you, your type.
----
Stating the very simpleton points of even having a lemonade stand work out doesn't impress me, nor should you have wasted your time doing it.
Now, let's recap my point: " So people have to realize fancy new tech costs money, and they aren't getting raked over the coals."
--
That's a direct quote.
I also will reobject your own stupidty : " You're forgetting that R&D costs are not just "whatever they will be" but are based off what the market will support via purchasing the end result."
PLEASE SEE TESLA PRICES.
--
Another jerkoff that is SOOOOOOOO stupid, finds it possible that someone would even argue that gamers should just spend more money on a card, and - after pointing out that's ridiculous, feels he has made a good point, and claims, an understanding of economics.
-
If you don't see the hilarity in that, I'm not sure you're alive.
-
Where do we get these brilliant analysts who state the obvious a high schooler has had under their belt for quite some time ?
--
I will say this much - YOU specifically (it seems), have encountered in the help forums, the arrogant know it all blowhards, who upon say, encountering a person with a P4 HT at 3.0GHZ, and a pci-e 1.0 x16 slot, scream in horror as the fella asks about placing a 4890 in it. The first thing out of their pieholes is UPGRADE THE CPU, the board, the ram, then get a card....
If that is the kind of thing you really meant to discuss, I'd have to say I'm likely much further down that bash road than you.
You might be the schmuck that shrieks "cpu limitation!, and recommends the full monty reaplcements"
--
Let's hope you're not after that simpleton quack you had at me.