The Radeon HD 4850 & 4870: AMD Wins at $199 and $299
by Anand Lal Shimpi & Derek Wilson on June 25, 2008 12:00 AM EST- Posted in
- GPUs
One, er, Hub to Rule them All?
With R500 AMD introduced its first ring bus, a high speed, high bandwidth bus designed to move tons of data between consumers of memory bandwidth and the memory controllers themselves. The R600 GPU saw an updated version of the ring bus, capable of moving 100GB/s of data internally:

On R600 the ring bus consisted of two 512-bit links for true bi-directional operation (data could be sent either way along the bus) and delivered a total of 100GB/s of internal bandwidth. The ring bus was a monster and it was something that AMD was incredibly proud of, however in the quest for better performance per watt, AMD had to rid itself of the ring and replace it with a more conventional switched hub architecture:
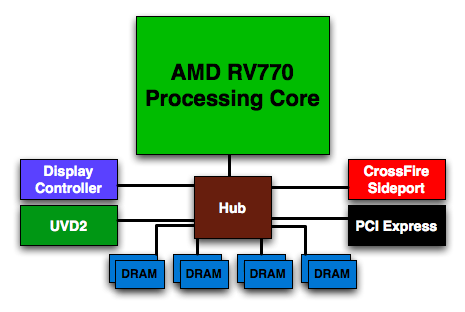
With the ring bus data needed to be forwarded from one ring stop to the next and all clients got access to the full bandwidth, regardless of whether or not they needed it. For relatively low bandwidth data (e.g. UVD2 and display controller data), the ring bus was a horrible waste of power.
With the RV770 all that exists is a simple switched hub, which means that sending data to the display controller, PCIe and UVD2 (AMD's video decode engine) traffic are now far less costly from a power standpoint. Another side effect of ditching the ring bus is a reduction in latency since data is sent point to point rather than around a ring. With the move to a hub, AMD increased their internal bus width to 2kbits wide (which is huge). Maximum bandwidth has increased to 192GB/s (in 4870) but this depends on clock speeds.
With nearly double the internal bandwidth and a point to point communication system, latency between memory clients should be decreased, and huge amounts of data can move between parts of the chip. Certainly getting enough data on to the GPU to feed 800 execution units is a major undertaking and AMD needed to make a lot of things wider to accommodate this.
The CrossFire Sideport
Although AMD isn't talking about it now, the CrossFire Sideport is a new feature of the RV770 architecture that isn't in use on the RV770 at all. In future, single-card, multi-GPU solutions (*cough* R700) this interface will be used to communicate between adjacent GPUs - in theory allowing for better scaling with CrossFire. We'll be able to test this shortly as AMD is quickly readying its dual-GPU RV770 card under the R700 codename.
One thing is for sure, anything AMD can do to assist in providing more reliable consistent scaling with CrossFire will go a long way to help them move past some of the road blocks they currently have with respect to competing in the high end space. We're excited to see if this really makes a difference, as currently CrossFire is performed the same way it always has been: by combining the output of the rendered framebuffer of two cards. Adding some sort of real GPU-to-GPU communication might help sort out some of their issues.








215 Comments
View All Comments
DevinCerly - Thursday, September 17, 2020 - link
https://mediahubofficialchannel.kofilms.info/ati-b...">[img]https://i.ytimg.com/vi/fqjU_OCZ4j4/hqdefault.jpg[/img]Ati BhoEpisode 0307-March-2020New Comedy https://mediahubofficialchannel.kofilms.info/ati-b...">SerialBy Media Hub Official Channel
GertieHuh - Friday, September 18, 2020 - link
https://teammojang.bgworld.info/ask-mojang/mbzCqMu...">[img]https://i.ytimg.com/vi/6XaGgppwjZM/hqdefault.jpg[/img]Ask https://teammojang.bgworld.info/ask-mojang/mbzCqMu...">Mojang #10: Electricity or Magic?
JuanitaBed - Saturday, September 19, 2020 - link
https://realpharmnutrition.plthrow.info/eng-sub/sp...">[img]https://i.ytimg.com/vi/M_m2tVwr7_o/hqdefault.jpg[/img]ENG SUB Mateusz Kieliszkowski x Konrad Karwat https://realpharmnutrition.plthrow.info/eng-sub/sp...">- trening hantla
Bettyabaws - Sunday, September 20, 2020 - link
https://joanaceddia.csgoal.info/lYBys6h-a2DdipU/pl...">[img]https://i.ytimg.com/vi/bJBNrF90yXc/hqdefault.jpg[/img]https://joanaceddia.csgoal.info/lYBys6h-a2DdipU/pl...">Playing A Horror Game
Holliebrill - Tuesday, September 22, 2020 - link
https://chelseatv.ilhistory.info/iIt8rbaeh9PI0rA/o...">[img]https://i.ytimg.com/vi/UZHHPlQpcqM/hqdefault.jpg[/img]Olivier https://chelseatv.ilhistory.info/iIt8rbaeh9PI0rA/o...">Giroud Winner Stuns VillaAston Villa 1-2 ChelseaUnseen Extra
Rosalynexete - Tuesday, September 22, 2020 - link
https://stay12.cscrone.info/iGWumpbSgXqoZWw/moje-s...">[img]https://i.ytimg.com/vi/V2u52oIFx58/hqdefault.jpg[/img]https://stay12.cscrone.info/iGWumpbSgXqoZWw/moje-s...">MOJE SETUP TOUR 2019
YolandaBob - Thursday, September 24, 2020 - link
https://tensai2407.trworld.info/aZ6Yg6HSp2dpw5Y/ms...">[img]https://i.ytimg.com/vi/3ehJilF65a4/hqdefault.jpg[/img]🥠مشكلتي Щ…Ш№ https://tensai2407.trworld.info/aZ6Yg6HSp2dpw5Y/ms...">Ш§Щ„ЩЉЩ€ШЄЩЉЩ€ШЁ Щ€ ЩЃЩЉЩЃШ§ Щ€ Ш§Щ„ШЩЉШ§Ш© Щ€ЩѓЩ„ ШґЩЉ
CelesteCen - Sunday, September 27, 2020 - link
https://onetwoonetwors.azfun.info/kXiV2b2zkc3NsL4/...">[img]https://i.ytimg.com/vi/-E4wXzZkhzY/hqdefault.jpg[/img]КОРОЧЕ ГОВОРЯ, Р§РРў-КОДЫ https://onetwoonetwors.azfun.info/kXiV2b2zkc3NsL4/...">Р’ РЕАЛЬНОРМ† Р–РР—РќРР§РРўР«, РГРА Р’ РЕАЛЬНОСТР
EvelynBeece - Tuesday, September 29, 2020 - link
https://flashgitzanimation.seworld.info/qY3ImZLdZ4...">[img]https://i.ytimg.com/vi/sUd4-y1ROgM/hqdefault.jpg[/img]PUTTING https://flashgitzanimation.seworld.info/qY3ImZLdZ4...">AN END TO THIS
BrendaDeast - Thursday, October 1, 2020 - link
https://topg33ks.ilmem.info/z-mh/tKfLZ5h-r4KKZL4.h...">[img]https://i.ytimg.com/vi/SBe1bLzOQ1Y/hqdefault.jpg[/img]ЧђЧ– ЧћЧ” ЧћЧ—Ч›Ч” ЧњЧ Ч• Ч‘Ч©ЧњЧ‘ 4 Ч©Чњ https://topg33ks.ilmem.info/z-mh/tKfLZ5h-r4KKZL4.h...">ЧћЧђЧЁЧ•Ч•Чњ?